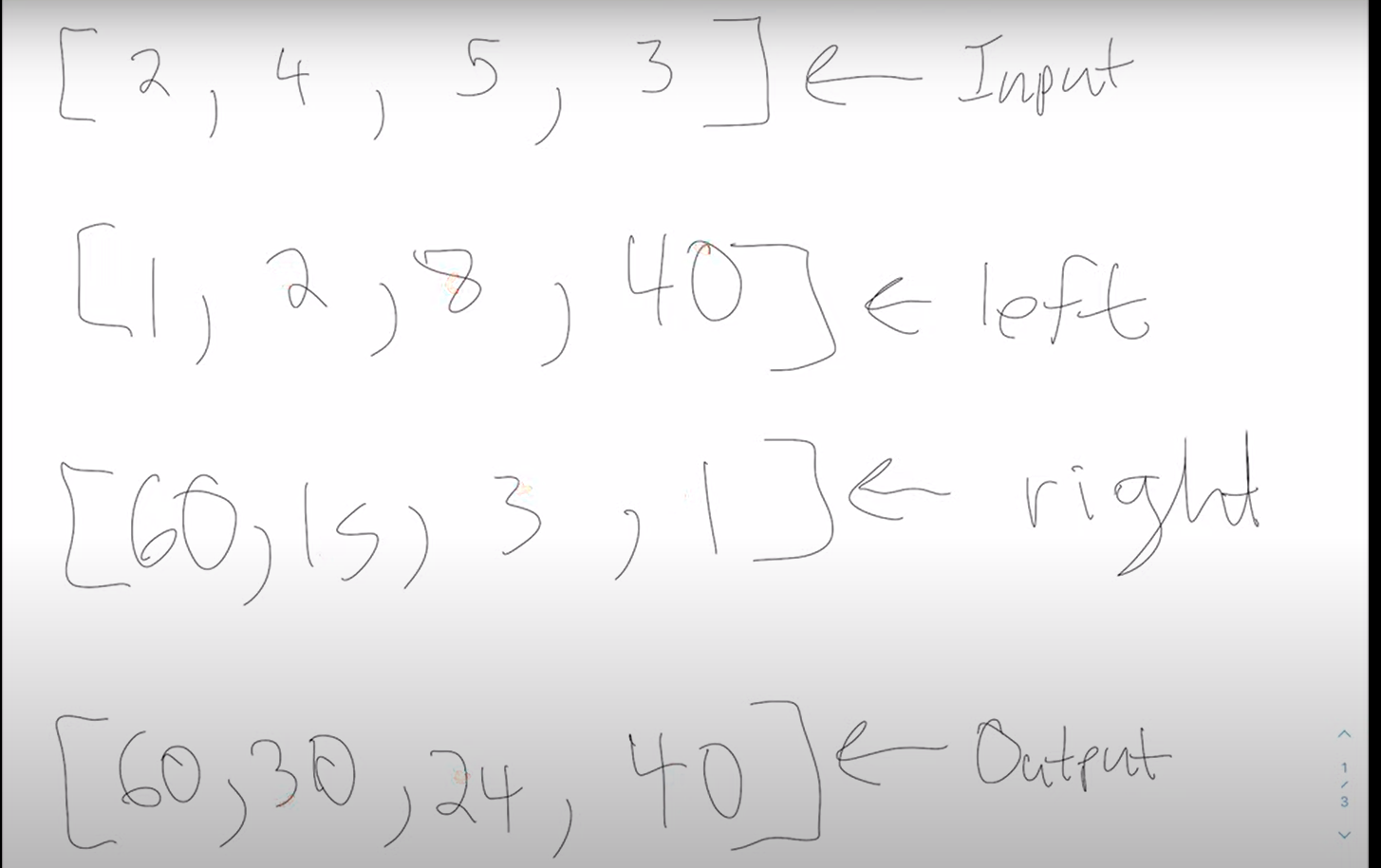Understand the problem Think about problems that you’ve done before that are similar to this one Run through a few small examples Ask clarifying questions
Brute force solution Often all permutations, all pairs etc. May not help you that much, because the optimal solution is often very different from the brute force But it’s better to have something rather than nothing
Try to match problem solving patterns to this problem You have a toolbox of data structures and algorithms at your disposal In cs61a, you learned a recursive way of thinking you can apply to a range of problems This course is designed to expand your toolbox
Implement your solution Once you figure out your approach, this is often muscle memory Run a test case Should I optimize further?
找出array里面两个元素,使得他们的和等于目标元素的值 Given an array of integers nums and an integer target, return indices of the two numbers such that they add up to target. You may assume that each input would have exactly one solution, and you may not use the same element twice. You can return the answer in any order.
1 2 3 4 5 6 7 8 9
classSolution: deftwoSum(self, nums: List[int], target: int) -> List[int]: d = {} for i , n inenumerate(nums): m = target - n if m in d: return [d[m],i] else: d[n] = i
找到元素间最大的差值,且小的在前大的在后 You are given an array prices where prices[i] is the price of a given stock on the ith day. You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock. Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.
1 2 3 4 5 6 7 8
classSolution: defmaxProfit(self, prices: List[int]) -> int: min_price ,max_price = float("inf") , 0 for price in prices: min_price = min (min_price,price) profit = price - min_price max_price = max(max_price,profit) return max_price
随时跟踪最小值和最大差值 这里没必要去跟踪最大值,要不然会引入新的变量
还有一种是跟踪相邻元素累计差值的,Kadane’s Algorithm,原先实现在largest sum contiguous array上,似乎c++更容易实现:
Given an array of intervals where intervals[i] = [starti, endi], merge all overlapping intervals, and return an array of the non-overlapping intervals that cover all the intervals in the input.
defmerge(self, intervals): out = [] for i insorted(intervals, key=lambda i: i.start): if out and i.start <= out[-1].end: out[-1].end = max(out[-1].end, i.end) else: out += i, return out
Given an integer array nums, return an array answer such that answer[i] is equal to the product of all the elements of nums except nums[i]. 输出除该元素外其他元素的乘积,复杂度O(n)且不能用除法
defproductExceptSelf(self, nums: List[int]) -> List[int]: n = len(nums) left = [] right = [1]*n ##预先设置好list的大小,从右向左改变内部的值。如果每次都resize会导致O(n^2) output = [] left_prod = 1 for el in nums: left.append(left_prod) left_prod *= el right_prod = 1 i = n-1 while i >= 0: right[i] = right_prod right_pod *= nums[i] i-=1 for i inrange(n): output.append(left[i]*right[i]) return output
Optimized:只用一个list
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
defproductExceptSelf(self, nums: List[int]) -> List[int]: n = len(nums) output = [1] * n
for i inrange(1, n): output[i] = output[i - 1] * nums[i - 1] prod = 1 i = n - 1 while i >= 0: output[i] *= prod prod *= nums[i] i -= 1 return output
给出两个linked list,每一位相加 You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order, and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
思路正常,看看python怎么写 这里尤其注意dummy = cur = ListNode(0)这样写是可以的
Given the head of a singly linked list, reverse the list, and return the reversed list.
思路好想,这里主要注意一下recursive方法
Iterative Solution. 一个一个修改node。注意edge case的处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: defreverseList(self, head: Optional[ListNode]) -> Optional[ListNode]: pre = None cur = head while cur: nxt = cur.next cur.next = pre pre = cur cur = nxt return pre
翻转linked list其中一部分node的顺序。 Given the head of a singly linked list and two integers left and right where left <= right, reverse the nodes of the list from position left to position right, and return the reversed list.
第一次做用了stack,才发现python里没有delete这种操作。“ If nothing points to the node (or more precisely in Python, nothing references it) it will be eventually destroyed by the virtual machine anyway.” python的del不同于C的free和C++的delete,实际上类似于解引用 。
classSolution: # @param head, a ListNode # @param m, an integer # @param n, an integer # @return a ListNode defreverseBetween(self, head, m, n): if m == n: return head
dummyNode = ListNode(0) dummyNode.next = head pre = dummyNode
for i inrange(m - 1): pre = pre.next # reverse the [m, n] nodes reverse = None cur = pre.next for i inrange(n - m + 1): next = cur.next cur.next = reverse reverse = cur cur = next
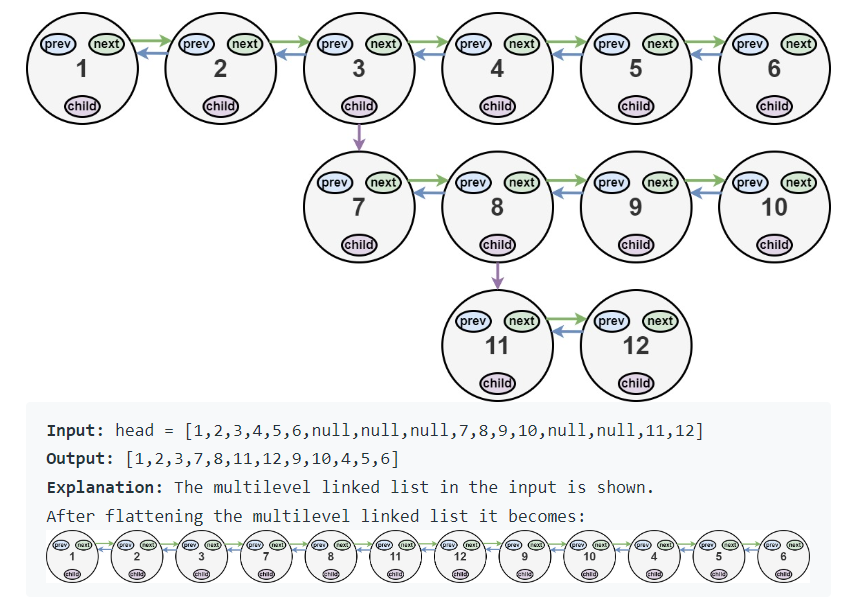
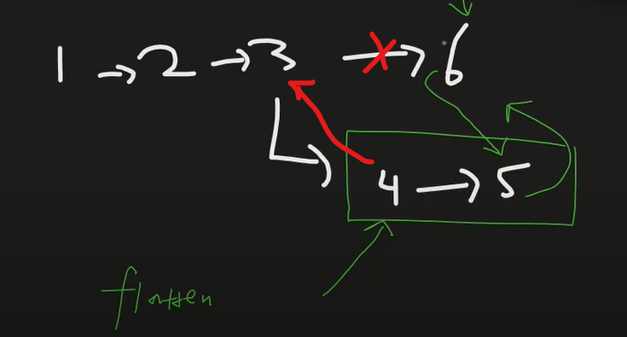
classSolution: defflatten(self, head: 'Optional[Node]') -> 'Optional[Node]': ptr = head while ptr: if ptr.child: # do something else: ptr = ptr.next return head
classSolution: deftail(self,head): tmp = head while tmp.next: tmp = tmp.next return tmp defflatten(self, head: 'Optional[Node]') -> 'Optional[Node]': ptr = head while ptr: if ptr.child: next_ptr = ptr.next flattened_child = self.flatten(ptr.child) ptr.next = flattened_child flattened_child.prev = ptr flattened_child_tail = self.tail(flattened_child) flattened_child_tail.next = next_ptr # Don't forget to consider the edge case, whether next_ptr is None or not if next_ptr: next_ptr.prev = flattened_child_tail ptr.child = None ptr = next_ptr #directly go to the node after the flattened sub linked list else: ptr = ptr.next return head
classSolution: defremoveNthFromEnd(self, head, n): defremove(head): ifnot head: return0, head i, head.next = remove(head.next) return i+1, (head, head.next)[i+1 == n] //if i+1== n, return head.next return remove(head)[1] //return head from a pair (index,node)
双指针解决 hint:Maintain two pointers and update one with a delay of n steps.Do this in one pass. 要学会常用for _ in range()这种语句
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defremoveNthFromEnd(self, head, n): fast = slow = head for _ inrange(n): fast = fast.next ifnot fast: return head.next while fast.next: fast = fast.next slow = slow.next slow.next = slow.next.next return head
用binary search,主要注意可以把matrix看作list,不要用nested while loop寻找行,列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defsearchMatrix(self, matrix: List[List[int]], target: int) -> bool: m,n = len(matrix),len(matrix[0]) left , right = 0, n*m-1 while left <= right: mid = (left + right) // 2 ele = matrix[mid // n][mid % n] if target < ele: right = mid - 1 elif target > ele: left = mid + 1 else: returnTrue returnFalse
还有一种方法使用bisect.bisect_left() bisect_left(list, num, beg, end) :- This function returns the position in the sorted list, where the number passed in argument can be placed so as to maintain the resultant list in sorted order. If the element is already present in the list, the left most position where element has to be inserted is returned. This function takes 4 arguments, list which has to be worked with, number to insert, starting position in list to consider, ending position which has to be considered.
1 2 3 4 5 6 7 8
classSolution: defsearchMatrix(self, matrix, target): i = bisect.bisect_left(matrix, [target]) ##找到行 if i < len(matrix) and matrix[i][0] == target: returnTrue row = matrix[i-1] j = bisect.bisect_left(row, target) return j < len(row) and row[j] == target
给定一个sorted list,返回target出现的起始位和末尾位 Given an array of integers nums sorted in non-decreasing order, find the starting and ending position of a given target value. If target is not found in the array, return [-1, -1].
两次binary search
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defsearchRange(self, nums, target): defsearch(n): lo, hi = 0, len(nums) - 1 while lo <= hi: mid = (lo + hi) // 2 if nums[mid] >= n: hi = mid - 1 else: lo = mid + 1 return lo ifnotlen(nums): return [-1,-1] lo = search(target) return [lo, search(target+1)-1] if target in nums[lo:lo+1] else [-1, -1] # slicing 如果越界了不会报错,会返回一个empty list
Because it’s not fully sorted, we can’t do normal binary search. But here comes the trick:
If target is let’s say 14, then we adjust nums to this, where “inf” means infinity: [12, 13, 14, 15, 16, 17, 18, 19, inf, inf, inf, inf, inf, inf, inf, inf, inf, inf, inf, inf]
If target is let’s say 7, then we adjust nums to this: [-inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
And then we can simply do ordinary binary search.
Of course we don’t actually adjust the whole array but instead adjust only on the fly only the elements we look at. And the adjustment is done by comparing both the target and the actual element against nums[0].
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defsearch(self, nums: 'List[int]', target: int) -> int: lo, hi = 0, len(nums) -1 while lo <= hi: mid = (lo + hi) // 2 num = nums[mid] if (nums[mid] < nums[0]) == (target < nums[0]) \ #如果nums[mid]和target在同一边,则返回nums[mid] else (-math.inf if target < nums[0] else math.inf) # 如果不是的话,将其返回成-INF or INF 以进行之后的binary search if num < target: lo = mid + 1 elif num > target: hi = mid - 1 else: return mid return -1
def__init__(self, w): """ :type w: List[int] """ self.w = w self.n = len(w) for i inrange(1,self.n): w[i] += w[i-1] self.s = self.w[-1]
defpickIndex(self): """ :rtype: int """ seed = random.randint(1,self.s) l,r = 0, self.n-1 while l <= r: mid = (l+r)//2 if seed <= self.w[mid]: r = mid - 1 else: l = mid+1 return l
或者用内置函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution:
def__init__(self, w: List[int]): self.probList = w for i inrange(1,len(w)): self.probList[i] += self.probList[i-1]
defpickIndex(self) -> int: maximum = self.probList[-1] n = random.randint(1,maximum) return bisect.bisect_left(self.probList, n)
# Your Solution object will be instantiated and called as such: # obj = Solution(w) # param_1 = obj.pickIndex()
给定一个list和一个threshold,找到最小的divisor,使得“ divide all the array by it, and sum the division’s result” “less than or equal to threshold”。
好像没啥说的,注意最后return left就行
1 2 3 4 5 6 7 8 9 10
classSolution: defsmallestDivisor(self, nums, threshold): l, r = 1, max(nums) while l <= r: mid = (l + r)//2 ifsum(ceil(num/mid) for num in nums) <= threshold: #注意一下这个语句的写法 r = mid - 1 else: l = mid + 1 return l
给定一个rows and columns sorted in ascending order的matrix, return the kth smallest element in the matrix.
方法一:Maxheap 因为python只有minheap,所以插入的元素要取相反数 缺点是没有利用Matrix是sorted这一个特点 The maxHeap will keep up to k smallest elements (because when maxHeap is over size of k, we do remove the top of maxHeap which is the largest one)
1 2 3 4 5 6 7 8 9 10
classSolution: defkthSmallest(self, matrix, k): m, n = len(matrix), len(matrix[0]) # For general, matrix doesn't need to be a square maxHeap = [] for r inrange(m): for c inrange(n): heappush(maxHeap, -matrix[r][c]) iflen(maxHeap) > k: heappop(maxHeap) return -heappop(maxHeap)
方法二:Minheap 从每一行的头一个元素开始,iterate k次
1 2 3 4 5 6 7 8 9 10 11 12
classSolution: defkthSmallest(self, matrix: List[List[int]], k: int) -> int: m, n = len(matrix), len(matrix[0]) # For general, the matrix need not be a square minHeap = [] # val, r, c for r inrange(min(k, m)): heappush(minHeap, (matrix[r][0], r, 0)) #先把每一行第一个push到minHeap中,并且记录行,列号
ans = -1# any dummy value for i inrange(k): ans, r, c = heappop(minHeap) if c+1 < n: heappush(minHeap, (matrix[r][c + 1], r, c + 1)) #把该行后一个元素push进去 return ans
classSolution: defkthSmallest(self, matrix, k): m, n = len(matrix), len(matrix[0]) # For general, the matrix need not be a square
defcountLessOrEqual(x): cnt = 0 c = n - 1# start with the rightmost column for r inrange(m): while c >= 0and matrix[r][c] > x: c -= 1# decrease column until matrix[r][c] <= x cnt += (c + 1) return cnt
left, right = matrix[0][0], matrix[-1][-1] ans = -1# any dummy value while left <= right: mid = (left + right) // 2 if countLessOrEqual(mid) >= k: #注意这里是 >= k,因为可能有相同元素出现 ans = mid right = mid - 1# try to looking for a smaller value in the left side else: left = mid + 1# try to looking for a bigger value in the right side
return ans
Week Four
From slides
Stacks, Heaps, Queues
Stacks in Python
Can implement with python list, collections.deque, queue.LifoQueue Last In, First Out data structure (LIFO)
Functions associated with stack:
empty(): returns whether stack is empty - O(1)
size(): returns size of stack - O(1)
top(): returns element to topmost element of stack - O(1)
push(e): adds element ‘e’ to top of stack - O(1)
pop(): returns and deletes the topmost element of the stack - O(1)
# append() function to push # element in the stack stack.append('a') stack.append('b') stack.append('c')
print('Initial stack') print(stack)
# pop() function to pop # element from stack in # LIFO order print('\nElements popped from stack:') print(stack.pop()) print(stack.pop()) print(stack.pop())
print('\nStack after elements are popped:') print(stack)
# uncommenting print(stack.pop()) # will cause an IndexError # as the stack is now empty
Queues in Python
Can implement with python list, collections.deque, queue.Queue First In, First Out data structure (FIFO)
Functions associated with queues:
enqueue(): adds item to queue - O(1)
dequeue(): removes item from queue. items are popped in the same order as they are pushed - O(1)
# importing "heapq" to implement heap queue import heapq
# initializing list li = [5, 7, 9, 1, 3]
# using heapify to convert list into heap heapq.heapify(li)
# printing created heap print ("The created heap is : ",end="") print (list(li)) #The created heap is : [1, 3, 9, 7, 5]
# using heappush() to push elements into heap # pushes 4 heapq.heappush(li,4)
# printing modified heap print ("The modified heap after push is : ",end="") print (list(li)) #The modified heap after push is : [1, 3, 4, 7, 5, 9]
# using heappop() to pop smallest element print ("The popped and smallest element is : ",end="") print (heapq.heappop(li)) #The popped and smallest element is : 1
给定类似k[encoded_string]的string,return重复k个的 encoded_string 例如Input: s = “3[a]2[bc]”,Output: “aaabcbc”;Input: s = “3[a2[c]]”,Output: “accaccacc”
用stack解决。每次往stack里面存previous string,number of repetition,用变量记录current string。这样prevString + num*curString就可以做到前后衔接。 核心是如何找到最里层的string
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution(object): defdecodeString(self, s): stack = []; curNum = 0; curString = '' for c in s: if c == '[': stack.append(curString) stack.append(curNum) curString = '' curNum = 0 elif c == ']': num = stack.pop() prevString = stack.pop() curString = prevString + num*curString elif c.isdigit(): curNum = curNum*10 + int(c) else: curString += c return curString
甚至可以用regular expression 每次更新s值 re.sub(pattern, repl, string) The sub() function searches for the pattern in the string and replaces the matched strings with the replacement (repl). The repl could be a function
1 2 3 4
defdecodeString(self, s): while'['in s: s = re.sub(r'(\d+)\[([a-z]*)\]', lambda m: int(m.group(1)) * m.group(2), s) return s
给定一个string包含 ‘(‘, ‘)’, ‘{‘, ‘}’, ‘[‘ and ‘]’, 判断它是否valid。有以下要求: Open brackets must be closed by the same type of brackets. Open brackets must be closed in the correct order.
思路很好想,注意可以用dictionary简化代码
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defisValid(self, s: str) -> bool: stack = [] dict = {"]":"[", "}":"{", ")":"("} #注意通过closing来找opening for char in s: if char indict.values(): stack.append(char) elif char indict.keys(): if stack == [] ordict[char] != stack.pop(): returnFalse else: returnFalse returnnot stack
Given a string s of ‘(‘ , ‘)’ and lowercase English characters. Remove the minimum number of parentheses ( ‘(‘ or ‘)’, in any positions ) so that the resulting parentheses string is valid and return any valid string.
实现一个Least recently used (LRU) cache。要求get和put O(1) average time complexity. 这道题好奇怪,没有用到stack、queue、heap。O(1)的get首先确定了用dictionary。主要看一下怎么用double linked list记录insertion顺序
直接一个dictionary解决,因为dictionary会保留insert的顺序 (python 3.7 以后) 注意iter(),next()两个函数。他们可以用在list, set, tuple, etc.这里是dictionary python iter() method returns the iterator object,next() return the value
defget(self, key: int) -> int: if key notin self.dict: #判断句留意写法 return -1 val = self.dict.pop(key) #Remove it first before inserting it at the end again self.dict[key] = val return val
defput(self, key: int, value: int) -> None: if key in self.dict: self.dict.pop(key) else: iflen(self.dict) == self.capacity: del self.dict[next(iter(self.dict))] self.dict[key] = value
defget(self, key): if key in self.dic: n = self.dic[key] self._remove(n) self._add(n) return n.val return -1
defput(self, key, value): if key in self.dic: self._remove(self.dic[key]) n = Node(key, value) self._add(n) self.dic[key] = n iflen(self.dic) > self.capacity: n = self.head.next self._remove(n) del self.dic[n.key]
def_remove(self, node): p = node.prev n = node.next p.next = n n.prev = p
def_add(self, node): p = self.tail.prev p.next = node self.tail.prev = node node.prev = p node.next = self.tail
OrderedDict 实际上也是a HashMap and a Doubly Linked List 并且思路跟方法一差别不大
classSolution: defleastInterval(self, tasks: List[str], n: int) -> int: # tasks = ["A","A","A","B","B","B"] # n = 2 counts = list(collections.Counter(tasks).values()) # [3,3] max_count = max(counts) # 3 num_of_chars_with_max_count = counts.count(max_count) # 2, A and B num_of_chunks_with_idles = max_count-1# 2 -> A A A (except the last chunk)
# either a task will fill an empty place or the place stays idle, # either way the chunk size stays the same length_of_a_chunk_with_idle = n+1# 3 -> A _ _ A _ _ A
# on the final chunk, there will only be most frequent letters length_of_the_final_chunk = num_of_chars_with_max_count # 2
length_of_all_chunks = (num_of_chunks_with_idles*length_of_a_chunk_with_idle) + length_of_the_final_chunk # 2*3 + 2 = 8 # -> A B _ A B _ A B
# Your MinStack object will be instantiated and called as such: # obj = MinStack() # obj.push(val) # obj.pop() # param_3 = obj.top() # param_4 = obj.getMin()
# Your UndergroundSystem object will be instantiated and called as such: # obj = UndergroundSystem() # obj.checkIn(id,stationName,t) # obj.checkOut(id,stationName,t) # param_3 = obj.getAverageTime(startStation,endStation)
Implement the Twitter class: Twitter() Initializes your twitter object. void postTweet(int userId, int tweetId) post a new tweet List<Integer> getNewsFeed(int userId) Retrieves the 10 most recent tweet IDs posted by users who the user followed or by the user themself. Tweets must be ordered from most recent to least recent. void follow(int followerId, int followeeId) The user with ID followerId started following the user with ID followeeId. void unfollow(int followerId, int followeeId) The user with ID followerId started unfollowing the user with ID followeeId.
def__init__(self): """ Initialize your data structure here. """ self.tweets = collections.defaultdict(list) self.following = collections.defaultdict(set) self.order = 0 defpostTweet(self, userId, tweetId): """ Compose a new tweet. :type userId: int :type tweetId: int :rtype: void """ self.tweets[userId] += (self.order, tweetId), # identical to self.tweets[userId].append((self.order, tweetId)) # or self.tweets[userId] += [(self.order, tweetId)] # comma represent a list self.order -= 1#As default sorting will sort the items in ascending order
defgetNewsFeed(self, userId): """ Retrieve the 10 most recent tweet ids in the user's news feed. Each item in the news feed must be posted by users who the user followed or by the user herself. Tweets must be ordered from most recent to least recent. :type userId: int :rtype: List[int] """ tw = sorted(tw for i in self.following[userId] | {userId} for tw in self.tweets[i])[:10] # for Id in self.following[userId] | {userId}: #{userId} is a set # for tw in self.tweets[Id]: # temp.append(tw) # tw = sorted(temp)[:10] return [news for i, news in tw]
deffollow(self, followerId, followeeId): """ Follower follows a followee. If the operation is invalid, it should be a no-op. :type followerId: int :type followeeId: int :rtype: void """ self.following[followerId].add(followeeId)
defunfollow(self, followerId, followeeId): """ Follower unfollows a followee. If the operation is invalid, it should be a no-op. :type followerId: int :type followeeId: int :rtype: void """ self.following[followerId].discard(followeeId) #discard will not raise an error when the element is not found
# Your Twitter object will be instantiated and called as such: # obj = Twitter() # obj.postTweet(userId,tweetId) # param_2 = obj.getNewsFeed(userId) # obj.follow(followerId,followeeId) # obj.unfollow(followerId,followeeId)
dictionary + deque heapq.merge()will merge two sorted array, and return a iterator * unpacking iterator
defgetNewsFeed(self, userId): tweets = heapq.merge(*(self.tweets[u] for u in self.followees[userId] | {userId})) # * unpacks each element of the above array into a function call heapq.merge(). Basically, each element of the array is now a separate argument.
return [t for _, t in itertools.islice(tweets, 10)]
defswapNodes(self, head: ListNode, k: int) -> ListNode: first = last = head for i inrange(1, k): first = first.next
null_checker = first while null_checker.next: last = last.next null_checker = null_checker.next first.val, last.val = last.val, first.val #python直接交换值的方法 return head
classSolution: defswapNodes(self, head: ListNode, k: int) -> ListNode: pre_right = pre_left = ListNode(next=head) right = left = head for i inrange(k-1): pre_left = left left = left.next null_checker = left while null_checker.next: pre_right = right right = right.next null_checker = null_checker.next if left == right: return head pre_left.next, pre_right.next = right, left left.next, right.next = right.next, left.next return head
Given a binary array nums, return the maximum number of consecutive 1’s in the array.
iterate the whole array
1 2 3 4 5 6 7 8 9 10 11
classSolution(object): deffindMaxConsecutiveOnes(self, nums): cnt = 0 ans = 0 for num in nums: if num == 1: cnt += 1 ans = max(ans, cnt) else: cnt = 0 return ans
给定一个integer array 和一个integer target,在array每一个元素前面加上 + or - 使得sum = target,返回不同组合的个数
用recursion做(DP)
第一遍很好想,但是没optimization所以会time exceed
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
deffindTargetSumWays(self, nums, S): index = len(nums) - 1 curr_sum = 0 return self.dp(nums, S, index, curr_sum) defdp(self, nums, target, index, curr_sum): # Base Cases if index < 0and curr_sum == target: #index < 0 means that we have used all the items in the array return1 if index < 0: return0 # Decisions positive = self.dp(nums, target, index-1, curr_sum + nums[index]) negative = self.dp(nums, target, index-1, curr_sum + -nums[index]) return positive + negative
defminWindow(s, t): need = collections.Counter(t) #hash table to store char frequency missing = len(t) #total number of chars we care start, end = 0, 0 i = 0 for j, char inenumerate(s, 1): #index j from 1,但是char还是第一个字符开始,因为list slicing最后一个字符不包含 if need[char] > 0: missing -= 1 need[char] -= 1 if missing == 0: #match all chars while i < j and need[s[i]] < 0: #remove chars to find the real start need[s[i]] += 1 i += 1 need[s[i]] += 1#make sure the first appearing char satisfies need[char]>0 missing += 1#we missed this first char, so add missing by 1 if end == 0or j-i < end-start: #update window start, end = i, j i += 1#update i to start+1 for next window return s[start:end]
detecting a cycle in the directed graph 使用topological sort 注意indegree的概念,以及如何构建adjacent matrix
BFS(Kahn’s algorithm)
1 2 3 4 5 6 7 8 9 10 11
boolcanFinish(int n, vector<vector<int>>& prerequisites){ vector<vector<int>> G(n); vector<int> degree(n, 0), bfs; for (auto& e : prerequisites) G[e[1]].push_back(e[0]), degree[e[0]]++; for (int i = 0; i < n; ++i) if (!degree[i]) bfs.push_back(i); for (int i = 0; i < bfs.size(); ++i) for (int j: G[bfs[i]]) if (--degree[j] == 0) bfs.push_back(j); return bfs.size() == n; }